OpenAI is reportedly asking contractors to upload real workplace deliverables like slide decks, spreadsheets, PDFs, code repos, and images paired with the original “ask” that produced them to help evaluate and train its next wave of AI agents. The clearest reporting so far comes via WIRED, with additional details echoed by TechCrunch.
This isn’t more data for the pile. It is a directional change: from internet-scale text toward office-scale reality, meaning the messy, formatted, context-heavy artifacts that actually move work forward. If you build, buy, or sell automation, this is a tell.
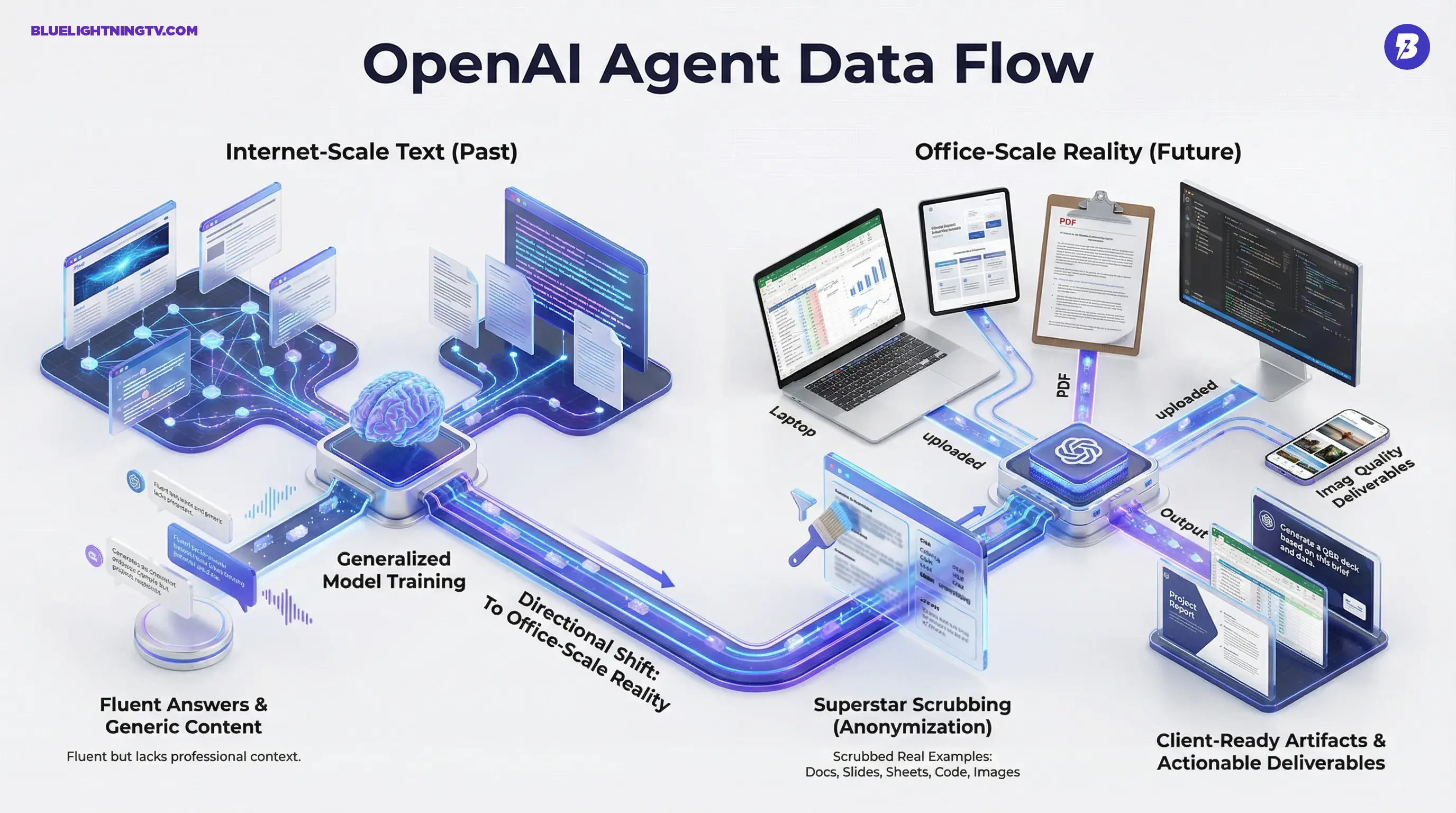
The headline shift: OpenAI appears to be training and evaluating agents on what finished work looks like, not just what good answers sound like.
What’s being collected
According to the reports, OpenAI (working through a third-party vendor and training data partner) is contracting people to submit real examples of professional work alongside the original request or brief. The goal is to create high-quality “input to output” pairs that mirror how work happens in the wild.
The submissions reportedly include a wide range of formats, exactly the stuff most AI demos conveniently avoid because it is hard to get right:
- Docs and PDFs (structured writing, layouts, citations)
- Slide decks (narrative plus design plus hierarchy)
- Spreadsheets (formulas, tables, business logic)
- Code repositories and scripts (implementation, not just snippets)
- Images and assets (visual deliverables, not just captions)
Contractors are reportedly instructed to remove identifying and proprietary information, and are given a scrubbing workflow that includes a ChatGPT custom GPT referenced as “Superstar Scrubbing” (also described as “Superstar Scrubber” in reporting) to help anonymize files before they are uploaded.
Why this is a big deal
Most models learned a lot of their “professional tone” from web text: blogs, docs, forum posts, and whatever else was crawlable or licensed. That gets you fluent outputs, but it does not reliably get you client-ready artifacts.
Real-world work has properties that web text does not:
- Formatting constraints (slides are not essays; spreadsheets are not paragraphs)
- Organizational patterns (templates, brand voice, house style)
- Context dependency (the brief matters as much as the output)
- Hidden rules (what gets included, what gets omitted, what gets escalated)
Agents, actual “do the task” systems, need those patterns. A model that can write a decent marketing plan is cute. A model that can take a messy brief and deliver a polished deck in the right structure is where automation starts eating serious workload.
The agent benchmark problem
If you are trying to build agents that handle multi-step knowledge work, you hit a brutal question fast:
How do you measure “good”?
It is easy to grade math. It is harder to grade “create a QBR deck the way a strong account manager would,” or “turn a vague exec email into a decision memo that will not get you roasted in a meeting.”
Real deliverables create a benchmark that is less subjective than vibes-based eval. Instead of “does this sound helpful,” you can ask:
- Did it follow the same structure humans use?
- Did it include the same sections and depth?
- Did it make the same tradeoffs?
- Does it match the format constraints of the tool?
That is why this specific kind of dataset is valuable. It is not just training fuel. It is evaluation scaffolding.
What changes for automation teams
If OpenAI (and others) succeed at this approach, here is what you should expect to shift in the product reality of agent tools. Not overnight, but directionally.
More “finished” outputs
Today, many AI workflows still look like: generate, copy, paste, format, clean up, and then make it look like we did it on purpose.
Training on real artifacts is a step toward outputs that arrive already shaped like something you would actually ship: deck-ready, sheet-ready, doc-ready.
Better multimodal handoffs
Pairing the prompt or brief with the artifact teaches the model that the request is part of the work, not just a preface. That matters for agentic behavior like:
- asking clarifying questions
- choosing a template
- deciding which details are required vs nice to have
- maintaining consistency across files (doc plus sheet plus slides)
Expanded “office tool” competence
Spreadsheets and slides are the graveyard of AI confidence. You can generate text about a model, but generating a spreadsheet that holds up when someone changes an input cell is a different sport.
This collection strategy strongly hints at an emphasis on the boring formats that run businesses, which is exactly where credible automation earns its keep.
The privacy tension (pragmatic version)
OpenAI and vendors can instruct contractors to scrub files, and they can add more scrubbing steps on their side. But the risk profile does not vanish just because you call it a protocol.
The practical issue is simple: a contractor is being asked to judge what counts as sensitive. In many workplaces, even employees do not have perfect clarity on what is protected by policy, client agreements, or NDAs, let alone third-party contractors working from memory and file folders.
Here is the core tension businesses should clock:
- The more real the work is, the more useful it is for training and evaluating agents
- The more real the work is, the more likely it contains patterns you would not want externalized
That does not automatically make the program bad. It just means the industry is walking into a familiar tradeoff: capability gains require tighter data discipline.
If your automation strategy relies on proprietary workflows, “scrubbing” cannot be a vibes-based step. It has to be operational.
What this signals about OpenAI’s roadmap
You do not pay for piles of slides and spreadsheets because you want a slightly better chatbot. You do it because you want models that can:
- operate across tools
- follow business conventions
- produce deliverables that match human standards
- get graded against real-world outputs
That aligns with the broader agents push: systems that plan, execute, and iterate across tasks, especially the high-volume, high-context work inside agencies, ops teams, marketing orgs, finance teams, and product shops.
And crucially: it suggests OpenAI is prioritizing the last mile of usefulness, the stuff between good answer and done.
What to watch next
This story matters less as a one-off program and more as a pattern other vendors will copy. If you are building workflows around AI (or selling AI-enabled services), these are the practical watchpoints.
Dataset provenance gets competitive
Tools that feel shockingly competent at your job usually have one secret: they have seen a lot of your kind of work before. Expect more vendors to chase similar pipelines to avoid being stuck with generic internet competence.
Evaluation becomes product
As agents ship into office tooling, vendors will need credible ways to say: “this agent can do X at Y quality.” Real artifacts make that measurable, which means benchmarks will start showing up in marketing, procurement, and enterprise trials.
File-native experiences accelerate
If models learn from artifacts, products will lean into artifacts. More native generation inside slides, sheets, docs, design files. Less “paste this into PowerPoint and pray.”
Quick snapshot
| What OpenAI wants | Why it matters | What it could unlock |
|---|---|---|
| Real deliverables plus original requests | Better training plus better eval for agents | Decks, sheets, docs that look truly finished |
| Multi-format files (PDF, PPT, XLSX, code) | Moves beyond “just text” competence | Stronger tool-using, file-native agents |
| Scrubbed and anonymized work artifacts | Enables use of realistic data (with risk) | More realistic business workflows in models |
The bottom line
OpenAI asking for real work files is a signal that the next battleground is not “can the model write.” It is can the agent deliver, in the formats, constraints, and conventions that creators and teams actually use every day.
For automation-driven businesses, this points to a near future where the best AI systems do not just help you think. They ship the work with you. The upside is speed and polish. The cost is that data governance stops being optional, because the training pipeline is getting uncomfortably close to the way real organizations operate.