Lightricks just made a very specific (and very creator-friendly) move: it open-sourced LTX-2, an audio-video generative model that outputs video with native, synchronized audio and it is designed to run locally. In a world where AI video often means silent clips that still need a full audio pass, LTX-2 is aiming at the messiest part of production: getting something that feels like a real piece of media, not just moving pixels.
The headline is not just open weights (though that matters). It is that Lightricks is treating sound as first-class in generative video. Dialogue, ambience, music, SFX those elements are usually bolted on afterward, stitched together in separate tools, and then synced with varying levels of pain. LTX-2s bet is that creators do not want another tab. They want a clip that plays.
What actually shipped
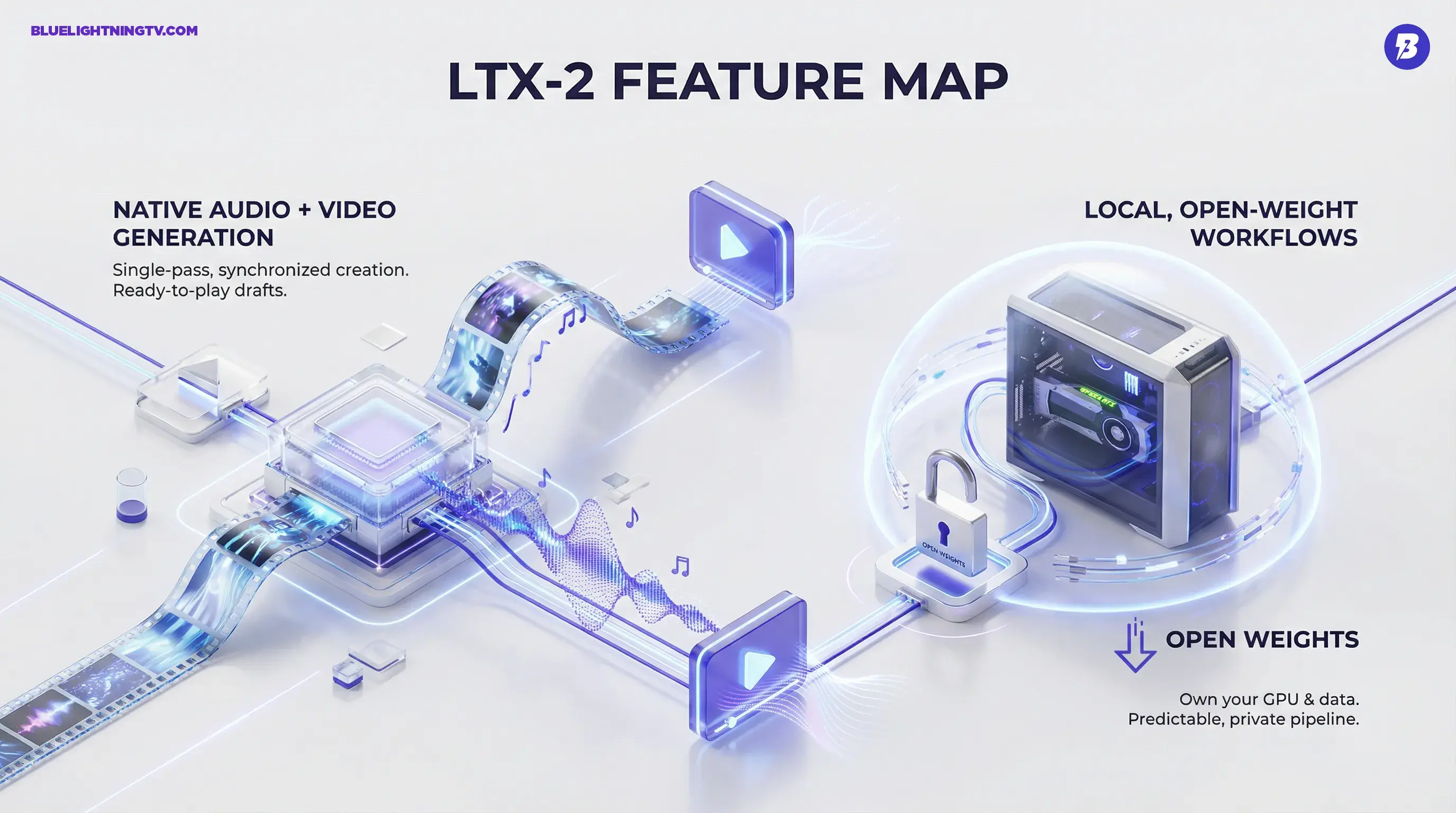
LTX-2 is positioned as a complete audio-video foundation model, released with model code and weights through Lightricks official channels. The practical promise: generate a short video sequence and get matching audio in the same pass, rather than treating audio like the afterthought you panic-fix at 1:47 a.m.
There is also a broader ecosystem angle: Lightricks is publishing tooling for inference and extension, including LoRA training and trainer code (not just a locked demo). That matters because open in AI video has often meant you can look, but do not touch. LTX-2 is more like: Here are the parts. Build your pipeline.
| Piece | What it is | Why creators care |
|---|---|---|
| Open weights | Downloadable checkpoints | Local runs, private pipelines, custom tuning |
| Native audio | Audio generated with video | Fewer handoffs; less Frankenstein post |
| Local-first posture | Built to run on GPUs creators own | Predictable costs + better privacy control |
Why audio changes everything
Most generative video tools have trained creators to expect the silent movie workflow: generate visuals, export, then rebuild the emotional reality with audio elsewhere. That is fine for moodboards. It is not fine when you need a concept to land with a client, or you need an ad variant to feel finished enough to test.
LTX-2s native audio shifts what a first draft looks like. Instead of a clip that needs narration, music, SFX, timing, and cleanup, you can potentially get a single artifact that is already communicative. Not perfect. But closer to shippable. And that is the point.
The real advantage is not sound exists. It is that sound is time-locked to the visual generation, so your draft plays like a scene not a slideshow with vibes.
Open-weight, real implications
Open-weight releases are not automatically a win for every creator but for teams that care about control, LTX-2 lands in a sweet spot. Running locally means:
- Privacy by default: client footage, unreleased product shots, internal storyboards stay in-house.
- Predictable iteration: no per-minute cloud pricing surprises mid-sprint.
- Customization is real: open weights make fine-tuning and style specialization possible (and that can include sound identity, not just visuals).
And this is where LTX-2 feels like it is responding to the current creator market: the demand is not just better generations, it is repeatable workflows. The ability to build a process around a model rather than visiting a web app like it is a carnival ride.
Specs creators will ask
Lightricks is framing LTX-2 around production-ready targets: high resolution, high frame rates, and short clips that can be stitched into longer sequences. Public materials around the release point to support for up to 4K output, and Lightricks has also highlighted up to 50 fps for 4K in their distilled setup.
On clip length, the current public docs and model materials emphasize short clips as the core unit for generation rather than long continuous scenes. (In practice, teams should expect to stitch shots together.)
It is also designed around efficiency, with an emphasis on being usable on consumer GPUs. In practice, LTX-2 is optimized for NVIDIA RTX-class GPUs and includes quantized variants to reduce memory pressure, which helps it live in the same world as the creator workstation not just the you will need a data center world.
If you want the model distribution details and setup entry points, the most direct sources are the official GitHub repo and model listing: GitHub: LTX-2 and Hugging Face: Lightricks/LTX-2.
| Capability | What LTX-2 targets | Where it lands |
|---|---|---|
| Video+audio output | Single-pass synchronized generation | Pitch comps, concept ads, previz |
| High-res posture | Up to 4K-capable output (with upscaling pipeline support) | Brand content that can survive review |
| Local deployment | Run without cloud dependency (RTX-focused) | Agency, studio, in-house teams |
Where it fits in pipelines
LTX-2 is not trying to replace your editor. It is trying to replace the part of your week that disappears into make 20 versions so we can decide what we want. That is why the local + open combo matters: you can prototype fast and then either cut in your normal stack or wire it into an internal tool.
Three places this lands immediately for working teams:
Pitch comps that play
Silent AI video is fine until you are pitching something that lives or dies on mood, timing, and energy. Native audio gives you a draft that communicates intent more clearly especially for ads, trailers, or cinematic beats where music and ambience do half the storytelling.
Variant factories for social
Short-form teams do not need one perfect video. They need ten viable options that can be tested, localized, and iterated. If the audio comes with the generation, the bottleneck moves from post-production glue to creative selection, which is a much better problem.
On-prem experimentation
Some teams simply cannot ship assets into a cloud tool, even if it is secure. Open weights plus local inference gives those groups a path to generative video experimentation without the compliance gymnastics.
Pragmatic limits to expect
This is a meaningful release, but it is not a magic wand. A few practical expectations are worth setting because the fastest way to hate a tool is to expect it to replace three departments on day one.
Audio will vary by scene
Generating coherent audio that matches visuals is a hard problem, especially when you expect clean dialogue, stable lip sync, and believable ambience. Expect stronger results on simpler, more obvious scenes and more uneven output as you push into complex action or dense sound design. The model documentation also notes that some audio types can be lower quality depending on the content.
Short clips are the unit
LTX-2 is built for short sequences that can be stitched. That is still the current reality of high-quality generative video: you build scenes out of shots, not feature films out of one prompt.
Local does not mean effortless
Running locally is empowering, but it also means you own the setup, the compute constraints, and the workflow integration. The upside is control. The cost is you are now the ops team (even if it is just you and your GPU).
The bigger signal
LTX-2 is part of a broader shift in generative media: tools are moving from look what I made to can I actually ship this? The fastest path to shippable is not always higher resolution or longer clips. It is workflow completeness.
Adding audio natively is one of the most practical completeness upgrades we have seen in open-weight video. And making it runnable locally is an even louder statement: creators and teams want ownership, not just access.
The competitive landscape is still packed with strong video generators, but Lightricks is carving a distinct lane here: open, local, audiovisual. If that combo holds up in real-world use, it will not just be another model release it will be a new baseline for what creators expect from AI video in 2026.