
Google DeepMind just dropped the Gemma 4 family of open-weight models, and the headline is not bigger numbers. It is that the release is built for creators and builders who want local, multimodal capability without living inside someone else’s API rules. The biggest shift: Gemma 4 moves to an Apache 2.0 license, which puts it in a very different category from the open-ish releases we have gotten used to.
If you want the official jumping-off point, start with the Hugging Face model page for the flagship: Gemma-4-31B.
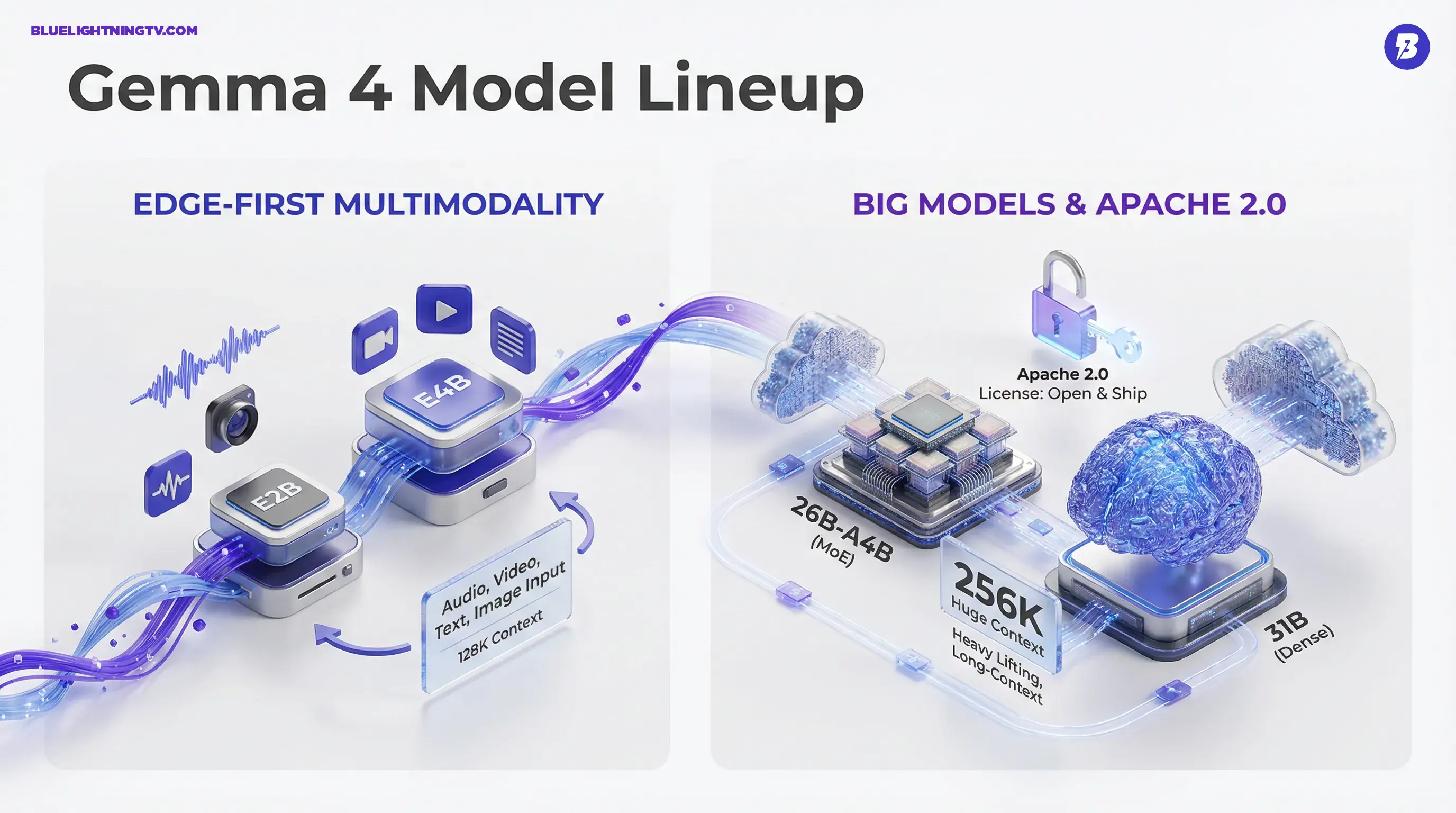
Gemma 4 comes as a lineup: smaller models meant for edge and on-device work, plus two bigger models designed for heavier reasoning and long-context jobs. And unlike a lot of releases that claim multimodal then quietly mean we added image captions, Gemma 4 is positioned as a practical multimodal toolkit: text + image + video across the family, with audio input on the smaller E-series models.
What actually shipped
Gemma 4 is a four-model family:
- Gemma-4-E2B (edge-focused)
- Gemma-4-E4B (edge-focused)
- Gemma-4-26B-A4B (Mixture-of-Experts)
- Gemma-4-31B (dense flagship)
Two details matter immediately for working creators:
- Context windows are huge. The larger models go up to 256K tokens; the smaller ones go to 128K.
- Modalities vary by size. All models support text + image + video, and the smaller E models also support audio input.
For a broader overview across the family, Hugging Face’s launch post is a good reference point: Welcome Gemma 4.
The license change matters
Let’s not bury the lede: Apache 2.0 is the kind of licensing creators notice after they have been burned once.
With Apache 2.0, Gemma 4 is viable for:
- shipping inside commercial products,
- redistribution (with the usual Apache 2.0 notice requirements),
- modification and fine-tuning without weird model license gotchas.
That is a cleaner runway than prior custom or community licenses that look permissive until your legal team reads the footnotes.
Multimodal, but targeted
Multimodal can mean anything from it will not crash if you attach an image to it to it can actually reason over mixed media. Gemma 4’s more interesting story is how the multimodality is distributed.
E-series: edge media brains
The E2B and E4B models are designed for on-device and edge scenarios and add audio input on top of text, image, and video. That is a creator-friendly combo for workflows like:
- turning rough audio into structured notes,
- classifying or tagging clips as you ingest them,
- building watch plus listen plus summarize automations that do not need a cloud hop.
NVIDIA frames these as models intended to bring multimodal understanding closer to devices and local GPUs: NVIDIA on Gemma 4 at the edge.
Big models: long context, heavy lifting
The 26B-A4B and 31B models are where the 256K context and higher ceiling matter. For creators, that is less chat and more system: you can keep large project state in one place, scripts, style constraints, prior drafts, brand voice, plus reference material, and still have room for iteration.
A practical way to think about it:
If you are building a content machine, long context is the difference between helpful assistant and consistent collaborator.
Model lineup at a glance
Here is the quick comparison that matters when you are deciding what to test first.
| Model | Best for | Notable traits |
|---|---|---|
| E2B | On-device workflows | 128K context, includes audio input |
| E4B | Stronger edge builds | 128K context, includes audio input |
| 26B-A4B (MoE) | Efficient big model use | MoE design with about 3.8B to 4B active parameters per token, 256K context |
| 31B (dense) | Max capability | Dense compute, 256K context |
MoE vs dense is worth a quick pause. The 26B-A4B model is a Mixture-of-Experts design, meaning only a smaller subset of parameters is active per token at inference, which can reduce compute versus a similarly sized dense model. The 31B is the dense flagship.
NVIDIA’s role: speed meets reality
Open weights are only as useful as your ability to run them without turning your workstation into a space heater with feelings.
NVIDIA’s guidance around Gemma 4 focuses on getting these models running efficiently across NVIDIA hardware, leaning on creator-relevant levers like quantization and optimized inference paths.
What changes in practice:
- Local inference becomes less of a science project. If you are already using NVIDIA GPUs for video work, the path to run the model where the footage lives gets shorter.
- Iteration gets faster. Creators do not need theoretical maximum quality; they need good, fast, repeatable for captioning, cutdowns, asset QA, and scripting.
- Cost becomes predictable. You are trading token meters for hardware utilization. That is not always cheaper, but it is often easier to plan around.
What it unlocks for creators
Gemma 4 is not a lifestyle brand. It is a pile of capability you can actually deploy. The most immediate creator wins show up in three places.
1) Long-context production systems
256K context means you can keep far more project truth in-window:
- series bible plus tone rules,
- sponsor constraints,
- past episodes,
- reference docs,
- revision history.
That is how you stop your model from forgetting the thing you reminded it of two messages ago.
2) Multimodal review loops
Even if you are not generating images or video, multimodal input is huge for review and QA:
- Does this thumbnail match our brand rules?
- Summarize what happens in these clips.
- Pull the three best soundbites from this segment.
The models do not need to replace a human editor. They just need to shrink the time between I have footage and I have decisions.
3) Productizable automation
Apache 2.0 plus a range of sizes makes it easier to build tools you can actually ship, especially internal tools that do not justify an ongoing per-token bill, or client work where data locality matters.
The pragmatic catch: big context is not free
There is a small trap with long-context models: context is a budget, not a vibe.
Yes, 256K tokens means you can include a mountain of material. But latency, memory, and cost still scale with input size. The winning pattern is usually:
- keep a long-term memory store (RAG plus retrieval),
- feed only the relevant slices,
- reserve full-context runs for moments when you truly need the whole universe in-frame.
In other words: do not stuff the whole fridge into the blender just because the pitcher is bigger now.
What to watch next
Gemma 4’s release is a signal flare for where open is heading in creator tech:
- Edge-first multimodality (including audio) is becoming normal, not exotic.
- Licensing clarity is becoming competitive advantage.
- Model families matter more than single hero checkpoints, because creators need the right tool per workflow stage.
If you are building with open models, Gemma 4 is one of the more concrete, shippable drops we have seen: a usable license, a real range of sizes, and multimodal coverage that maps to how creators actually work, capture, cut, revise, publish, rather than just benchmark flexing.
And yes, we all know the internet will immediately ask if it kills some other model. The more useful question is simpler: can you run it, can you ship it, and does it make your pipeline faster this week? Gemma 4 is positioned to be a yes more often than most.





