
Google just gave Gemini 3 Flash a very creator-friendly superpower: Agentic Vision, a new way for the model to actively investigate images instead of doing the usual one-and-done glance and guess. The official announcement is here: Introducing Agentic Vision in Gemini 3 Flash.
This matters because modern creative work is drowning in visuals that are not pretty pictures. Think dashboards, design comps, screenshots, dense infographics, UI states, slide decks, and the cursed table someone exported from Excel in 2009. Those are not inspiration. They are inputs. And turning them into clean, structured output (a brief, a spec, a post, a script, a caption set) has been one of the most annoying bottlenecks in AI-assisted workflows.
Agentic Vision is Google’s attempt to fix that with a simple idea: if the model is not sure, it should go look again on purpose.
What actually shipped
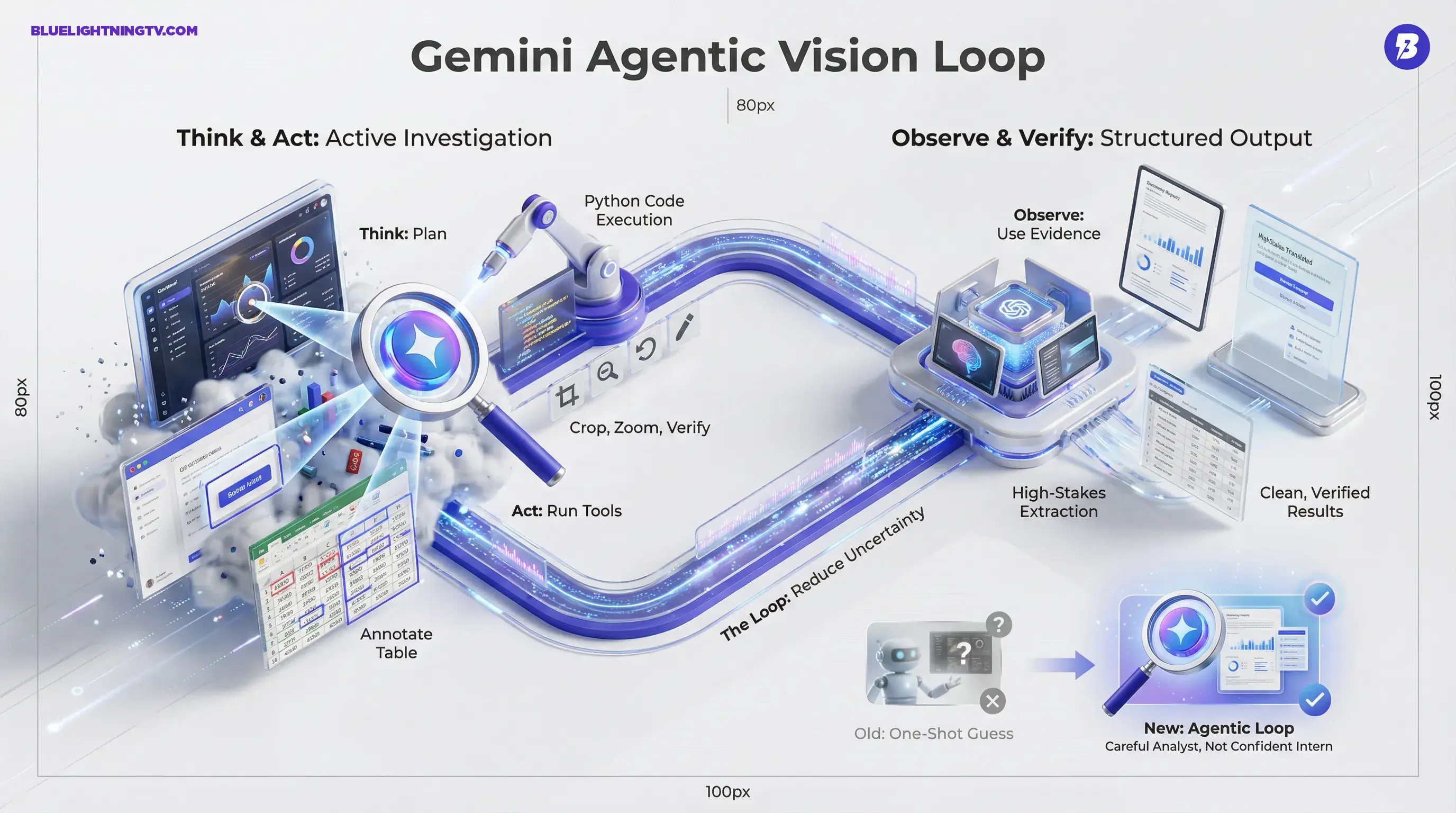
Agentic Vision is rolling out as a capability inside Gemini 3 Flash through the Gemini API, usable in Google AI Studio and Vertex AI. Google frames it as a shift from passive image understanding to an agentic Think to Act to Observe loop, where the model can plan steps, generate and execute Python code, manipulate the image (crop, zoom, annotate), and then use those results as evidence for its final answer.
If you want the platform level entry points, here are the two primary docs surfaces Google points developers to: Gemini API documentation and Google AI Studio.
Google says enabling this approach delivers a consistent 5 to 10 percent quality improvement across most vision benchmarks.
The headline feature is not better captions. It is process: the model can now behave less like a confident intern and more like a careful analyst. Still fast, but willing to double-check details when the image is dense.
Agentic beats one-shot
Most vision models still operate like this:
1) See image once
2) Produce answer
3) Hope nobody asks “where did you get that”
That is fine for “what is in this photo.” It is shaky for “read the tiny numbers in this chart, compare them, and summarize the outliers.”
Agentic Vision is designed to treat visual tasks more like investigation. It can decide it needs more clarity, then run steps to get it, like zooming into a specific region of a dashboard or isolating a table area before extracting values.
The quiet shift: Gemini is not just looking. It is operating on the image to reduce uncertainty, then answering from what it confirmed.
That is especially relevant to creators because your images are often functional artifacts, assets you need to convert into decisions, copy, or structured content.
The loop in plain English
Google’s Think, Act, Observe loop is basically:
Think: make a plan
The model decides what it needs to inspect. Not the whole image, the right parts.
Act: run visual actions
Using Python code execution, Gemini can manipulate the image: crop, zoom, rotate, annotate, and potentially compute things (like visual math and structured extraction) as part of its analysis.
Observe: use the evidence
Those manipulated views get added back into the context, and the model uses them to refine its interpretation before it answers.
The best part is what this implies: if the model is uncertain, it has a built-in mechanism to reduce uncertainty instead of improvising. That is a real quality-of-life upgrade for anyone using AI on production work where “close enough” becomes “why did we publish that.”
Where creators feel it
If you have ever tried to get an AI model to reliably interpret a screenshot of analytics, a UI mock, or a messy table, you already know the pain:
- it misses small labels
- it mixes up columns
- it invents numbers
- it treats UI hierarchy like a suggestion
- it confidently explains a chart it did not actually read
Agentic Vision is tuned for exactly those failure modes, because it gives the model tools to do what humans do naturally: zoom in, isolate, and verify.
Here are the creator workflows most likely to benefit first:
Dashboards into narratives
Turning screenshots of performance dashboards into clean summaries is a constant content ops task. Agentic Vision is positioned to reduce errors by focusing on the exact regions where metrics live, rather than summarizing the vibe of the chart.
UI screenshots into copy
UX writers and product marketers constantly translate UI states into release notes, docs, onboarding copy, and support content. A model that can iteratively check labels and structure can save time and reduce embarrassing mistakes.
Tables into structured output
If a table is dense, normal vision behavior often drops cells or merges rows. Agentic inspection makes it more likely the model extracts data cleanly or at least knows where it is uncertain.
Diagram interpretation
Flowcharts, funnels, and architecture diagrams are common in creative plus product teams. Agentic Vision is built for stepwise inspection, which should help when meaning depends on small arrows, labels, or nested groups.
Speed vs certainty tradeoff
The pragmatic caveat: agentic behavior can be slower. When a model is allowed to run multiple steps and execute code, it is doing more work than a one-pass vision response.
That is not a bug. It is the point. But it changes how you should think about using it:
- For lightweight tasks, a standard vision pass is fine.
- For high-stakes extraction (numbers, UI labels, compliance checks, spec details), the slower, more careful mode is worth it.
In other words: this is not “make AI vision faster.” It is “make AI vision less wrong when wrong is expensive.”
What’s included now
Here is the clean snapshot of what Google is signaling with this release:
| Capability | What it changes | Why creators care |
|---|---|---|
| Think Act Observe loop | Multi-step visual inspection | Better accuracy on dense visuals |
| Python code execution | Crop, zoom, rotate, annotate, plus compute | Fewer guessed details |
| Benchmark lift | Google reports 5 to 10 percent gains on most vision benchmarks | More usable output per attempt |
| API availability | Gemini API in AI Studio plus Vertex AI | Can plug into content pipelines |
Why this is a real signal
This launch fits a broader pattern: the industry is quietly admitting that raw model intelligence is not enough. Reliability is increasingly coming from systems, tool use, verification loops, and structured workflows that reduce hallucinations by design.
Agentic Vision is a particularly direct expression of that. It is not a promise that Gemini will never be wrong. It is a promise that, when code execution tools are available, it can behave more like a careful operator than a one-shot generator.
In creator terms: less “trust me,” more “here is what I checked.”
And that is exactly the shift that makes AI useful for day-to-day production, not just experimentation.
Availability, platforms
Google says Agentic Vision is available through Gemini 3 Flash via the Gemini API, accessible in Google AI Studio and Vertex AI. If you are deploying in Google Cloud, Vertex AI’s generative AI docs are here: Generative AI on Vertex AI.
For teams already building around Google’s ecosystem, the story here is straightforward: visual understanding is moving from nice demo to automation primitive. The moment AI can more reliably extract and verify information from screenshots and layouts, a lot of busywork (brief creation, reporting drafts, documentation updates) becomes scriptable.
Not magic. Just fewer hours of manual squinting at tiny UI text like it is an ARG.





