
OpenAI just rolled out an upgraded image generator inside ChatGPT, commonly described as ChatGPT Images 2.0, powered by the new model gpt-image-2. OpenAI’s announcement post is here: OpenAI: The new ChatGPT Images is here. And for developers, the model is live in the API as gpt-image-2.
The quick read: this is not OpenAI chasing another look how pretty moment. It is OpenAI trying to make images behave: follow instructions more reliably, hold a layout better, render text more legibly (especially short labels and headlines), and support iterative creative direction without you burning an hour on rerolls.
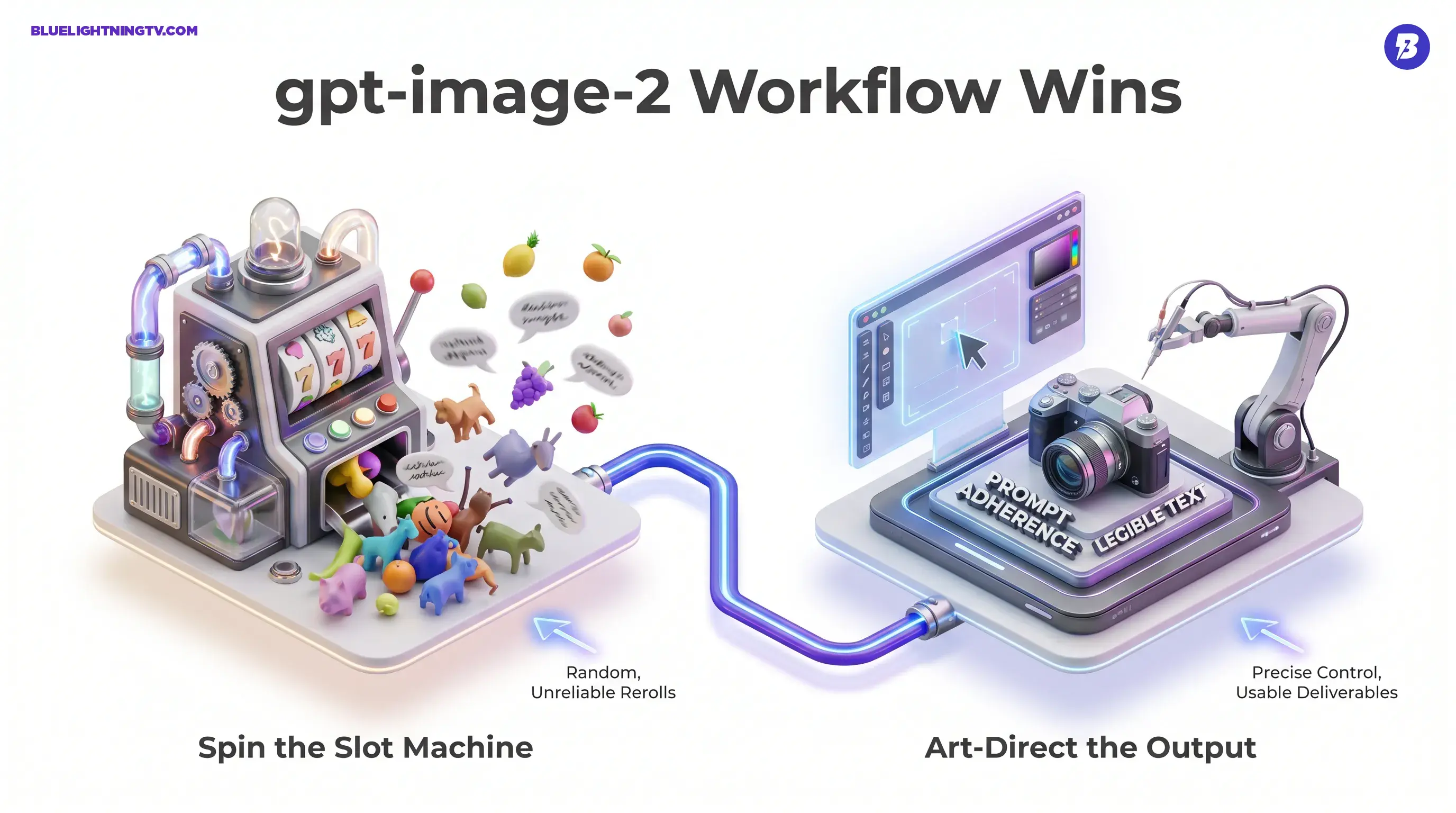
The shift creators will feel most: image generation is moving from spin the slot machine to art-direct the output.
What shipped
OpenAI’s upgrade has two parts that matter in practice: the model change (gpt-image-2) and the product behavior (how ChatGPT helps you iterate).
The model is available in ChatGPT and through the OpenAI Images API, which means it is not just a UI refresh. It is an engine update teams can wire into production workflows.
A few themes show up across OpenAI’s own framing and early hands-on usage: tighter instruction following, better text, better composition, and more predictable iteration. If you have been tracking this space, that is not random. Those are the exact failure points that keep AI images from becoming AI deliverables.
If you want the COEY take on why this matters operationally, see our related post: ChatGPT Images Upgrade Brings Real Scene Control.
The model change
OpenAI is calling the underlying engine gpt-image-2, and developers can target it directly in the API. That matters because it signals this is meant to be a platform capability, not a one-off ChatGPT feature.
If you are integrating, the canonical starting point is OpenAI’s Image Generation guide: Image generation (OpenAI API).
What got better
Let’s skip the confetti and talk about what actually improves creator workflows.
Prompt adherence
This is the unsexy superpower. Better prompt adherence means fewer it nailed the lighting but forgot the product generations. You can specify object counts, placements, and style constraints with a higher chance the output respects them.
In day-to-day creator terms: your prompt becomes more like a brief and less like a suggestion.
Text that reads
Text rendering is where most image models historically face-plant. OpenAI is emphasizing more legible in-image text, and early outputs line up with that direction: it is notably improved, though still not perfect.
This matters because a ton of commercial visuals are basically: image plus words. Thumbnails, posters, product promos, menus, slide-like graphics. If the model cannot spell, you are rebuilding type in Figma anyway and the AI speedup becomes a half-truth.
Composition that holds
The upgrade focuses on composition discipline: keeping elements separated, respecting negative space, and maintaining basic spatial logic.
No, it is not a layout engine where you drag boxes around. But the reliability jump matters because it reduces the most common time-sink: regenerating until the scene stops collapsing into visual mush.
Aspect ratios that match platforms
gpt-image-2 supports multiple aspect ratios and sizes, which is practical if you are shipping to multiple channels (YouTube, TikTok, Reels, display ads, banners, etc.). Instead of generating a square and praying a crop will not ruin it, you can generate closer to the target format.
Reasoning and iteration
The most interesting product layer here is that ChatGPT is not just generating an image and walking away. The workflow is trending toward iterative direction: generate, critique, adjust, regenerate, without losing context.
That sounds obvious, but it is a big deal because creative work is rarely one-shot. The winning workflow is almost always: keep everything, but change this.
If your image tool cannot support targeted iteration, it is not a collaborator. It is a mood board machine.
OpenAI is effectively pushing a more conversational art-direction loop, which fits how creators actually work: refinement over time, not one prompt to rule them all.
Who this helps most
This upgrade is strongest for creators whose visuals have to be useful, not just cool.
Thumbnail and social teams
Text plus composition upgrades are a direct hit for thumbnails, story cards, and social promos, where you need readable words, clean hierarchy, and consistent framing.
Marketing and brand studios
The model’s value here is less new aesthetic and more less cleanup. If outputs land closer to final, the role of Photoshop becomes finishing, not rescue.
E-commerce and product
Product storytelling often needs consistent sets: variations, angles, localized text, simple banners. The text and instruction-following improvements make AI output more viable for high-volume creative tasks.
Developers building pipelines
API availability means gpt-image-2 can show up inside tools, templates, and batch systems, especially where teams need to generate lots of structured variants quickly.
What is still not solved
Even with better control, creators should expect a few realities:
- Typography still is not deterministic. It is better, not perfect. For critical brand type, you will still want finishing tools.
- Complex layouts can still drift. The more constraints you stack, the more you will need iteration.
- Consistency is not the same as identity. Keeping a character or brand system stable across a long campaign may still require careful prompting, references, and human review.
This is a meaningful step forward, but it is not a replacement for design judgment. It is a reduction in friction, not a deletion of taste.
Quick feature snapshot
| Upgrade area | What’s improved | Why creators care |
|---|---|---|
| Instruction following | More faithful prompts and constraints | Fewer rerolls, faster usable hits |
| Text rendering | More legible in-image words (still not perfect) | Thumbnails, banners, UI-style comps |
| Composition control | More coherent scenes and placement | Less time fixing chaos in post |
| API access | gpt-image-2 available to devs |
Automate variants and pipelines |
The bigger signal
A lot of image-model discourse is trapped in aesthetics: who wins the wow frame. This launch is a reminder that the competitive edge is shifting toward control, consistency, and production readiness.
OpenAI’s move with ChatGPT Images 2.0 is basically: let’s make images usable for the jobs people actually do. That is not hype. That is a pretty pragmatic bet.
If you are a creator, the immediate implication is simple: you can spend less time wrestling the model and more time directing it. If you are a team, the deeper implication is even better: image gen is becoming something you can actually put into a repeatable pipeline, because the outputs are trending toward on-brief instead of surprisingly close.





