
OpenAI has rolled out GPT-5.5 inside ChatGPT and Codex, positioning it as a step forward in long-horizon, tool-using work, not just prettier responses. The official announcement is here: Introducing GPT-5.5.
The biggest shift is not “it’s smarter.” It is that OpenAI is clearly optimizing for automation that survives contact with reality: multi-step tasks, messy context, tool calls, and the kind of work that normally dies on step three because an earlier model forgot the plan.
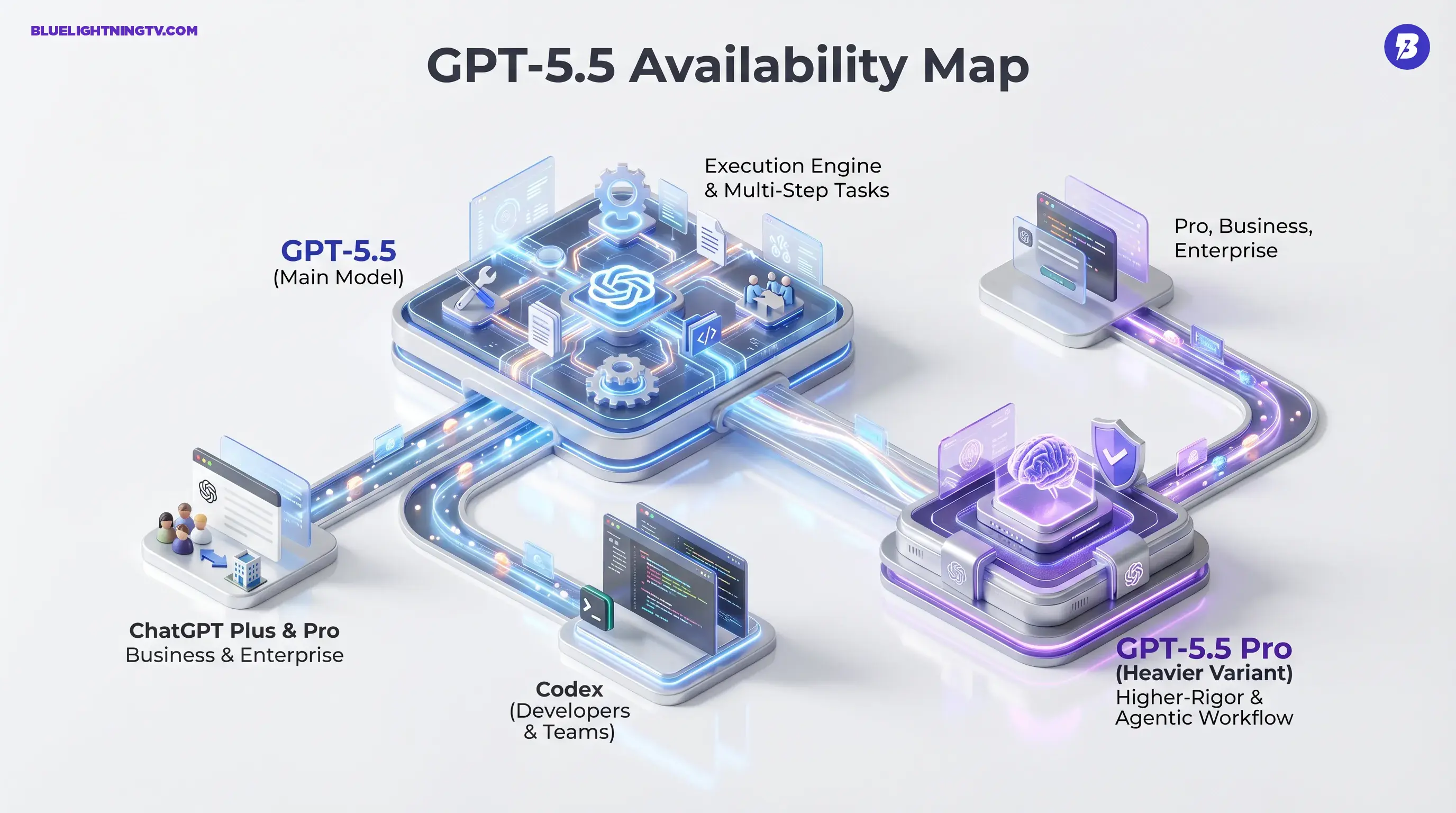
Translation for creators: GPT-5.5 is built for the unglamorous middle of the workflow: planning, executing, checking, and finishing, so you can spend your brainpower on taste and direction, not tab acrobatics.
What actually shipped
GPT-5.5 is available now in ChatGPT paid tiers (Plus, Pro, Business, Enterprise) and is also powering workflows in Codex, OpenAI’s code-focused environment. OpenAI is also rolling out a heavier variant, GPT-5.5 Pro, for Pro, Business, and Enterprise users inside ChatGPT, aimed at higher-rigor tasks.
OpenAI’s message is consistent across the announcement and supporting docs: GPT-5.5 is meant to be the default model for “real work” sessions, especially when that work requires tool use, long context, and staying on-task across a sequence.
Availability snapshot
| Surface | Who gets GPT-5.5 | What it’s for |
|---|---|---|
| ChatGPT | Plus, Pro, Business, Enterprise | Knowledge work plus tool workflows |
| ChatGPT (Pro variant) | Pro, Business, Enterprise | Higher-rigor reasoning runs |
| Codex | Available in paid access tiers | Agentic coding plus task execution |
Why GPT-5.5 matters
If you have been tracking OpenAI’s recent cadence, this release fits the direction they have been telegraphing: models are being shaped less as “answer machines” and more as execution engines that can move work forward inside a toolchain.
GPT-5.5’s practical promise is simple: fewer broken chains. Instead of you micromanaging a brittle prompt ladder, copy this into a doc, now paste into a sheet, now summarize, now reformat, GPT-5.5 is tuned to hold the plan, call tools, interpret results, and keep going.
The quiet product bet
OpenAI is betting that the next adoption wave does not come from one perfect output. It comes from:
- More tasks completed end-to-end in one session
- Less babysitting when steps involve tools and data
- Better self-correction when the model hits uncertainty
This is also why GPT-5.5 lands so cleanly next to OpenAI’s recent push into team automation, like Workspace Agents in ChatGPT. Models that cannot reliably execute multi-step work make “agents” feel like a demo. Models that can make teams start replacing glue work with systems.
For the COEY take on why Workspace Agents matter operationally, see: Workspace Agents Make ChatGPT Run Team Workflows.
Agent behavior, explained
OpenAI is explicit that GPT-5.5 is designed to plan and execute work with tools, and to improve how it monitors and verifies its own progress. That matters because most creator workflows are not “one prompt.” They are a loop:
- gather references
- extract constraints (voice, format, platform, audience)
- draft
- check against requirements
- revise
- package into deliverables
Earlier models could do each step, just not always coherently as a chain. GPT-5.5’s value is in making the chain less fragile.
Self-checking is the feature
OpenAI is highlighting improved “self-check” behavior: the model is better at looking at its own output, noticing gaps, and attempting corrections. That is not a vibe upgrade. It changes how you can safely use the model.
For teams, the win is not “trust it blindly.” It is more like:
Trust it to draft and verify cheaply, then put humans where the cost of being wrong is high (publishing, client deliverables, paid spend, claims).
OpenAI also published a system card for the release, which is usually where the most grounded details live: GPT-5.5 System Card.
Codex gets the upgrade
GPT-5.5 also shows up as a meaningful shift for Codex workflows. OpenAI is framing Codex as the place where “agentic” is not theoretical: the model is expected to handle longer tasks, interpret tool output, and keep a coherent plan across edits, tests, refactors, and fixes.
That matters even if you are not a “developer creator.” Most creator businesses are code-adjacent now: landing pages, tracking events, CMS scripts, automation glue, template logic, internal tools. The work is not always hard. It is just multi-step and annoying, which is exactly where agents either shine or faceplant.
What changes in practice
If GPT-5.5 holds up under real usage, the immediate behavior change is that more teams will start delegating tasks that were previously “not worth the overhead.” Think:
- Repo-level cleanup tasks (consistent naming, small refactors, documentation updates)
- Automation scripts for content ops (CSV cleanup, caption formatting, asset renaming)
- Bugfix loops that require running tests and interpreting failures
And yes, you still review diffs. You still run tests. The difference is whether the model can stay helpful after step five.
Speed and efficiency signals
OpenAI is also emphasizing efficiency: GPT-5.5 is positioned as matching GPT-5.4’s per-token latency while outperforming it on evaluations, and OpenAI says it uses fewer tokens for some coding workflows. For teams scaling usage, token efficiency is not a nerd detail. It is the difference between “we can run this daily” and “we can run this when the budget is feeling brave.”
That said, the cost story is not fully settled from an operator’s standpoint until API access is broadly available and teams see real-world token patterns across their own workloads.
API rollout is staged
OpenAI says API access is coming “very soon,” but it is not the headline today. The company has pointed to additional safeguards and deployment work before opening it up broadly through the API. If you are building production automations, that delay is annoying, but it is also a tell: OpenAI expects GPT-5.5 to be strong enough that deployment posture matters.
What creators should watch
GPT-5.5 will be judged less by cherry-picked demos and more by whether it is boringly dependable in three areas:
Long-run reliability
Can it keep the plan intact across a long session? Does it drift into side quests? Does it fail loudly when blocked, or quietly make something up to move forward?
Toolchain competence
Tool use is where models either become teammates or become liabilities. The question is whether GPT-5.5 can choose the right tool at the right time, interpret outputs correctly, and recover when something fails.
Team usability
The best agent is not the one that can do the most. It is the one a non-technical creator can steer safely: clear progress, controllable actions, and outputs that are easy to review.
OpenAI is clearly steering toward AI that operates, not just AI that talks. GPT-5.5 is the most direct expression of that shift in the core model line so far, and if it holds up, the near-term impact for creators will not be “more content.” It will be less grind between idea and shipped work.





