
OpenAI just made a very specific promise to creators: fewer tabs, fewer exports, fewer “we’ll fix it in post” lies we tell ourselves at 2 a.m. With Sora 2, OpenAI’s video generator can now output video and synchronized audio together in the same generation, dialogue, ambience, and sound effects included, so your first draft can actually sound like a first draft, not a silent movie with big dreams. The main announcement is on OpenAI’s site here.
This is news, not fantasy: Sora 2 is positioned as a unified audio plus video model, and OpenAI is framing it as a step toward near-finished clips straight from prompts. It’s also arriving in a more “product” shape than earlier Sora teases, paired with a dedicated Sora experience and a staged rollout that’s clearly designed to scale carefully.
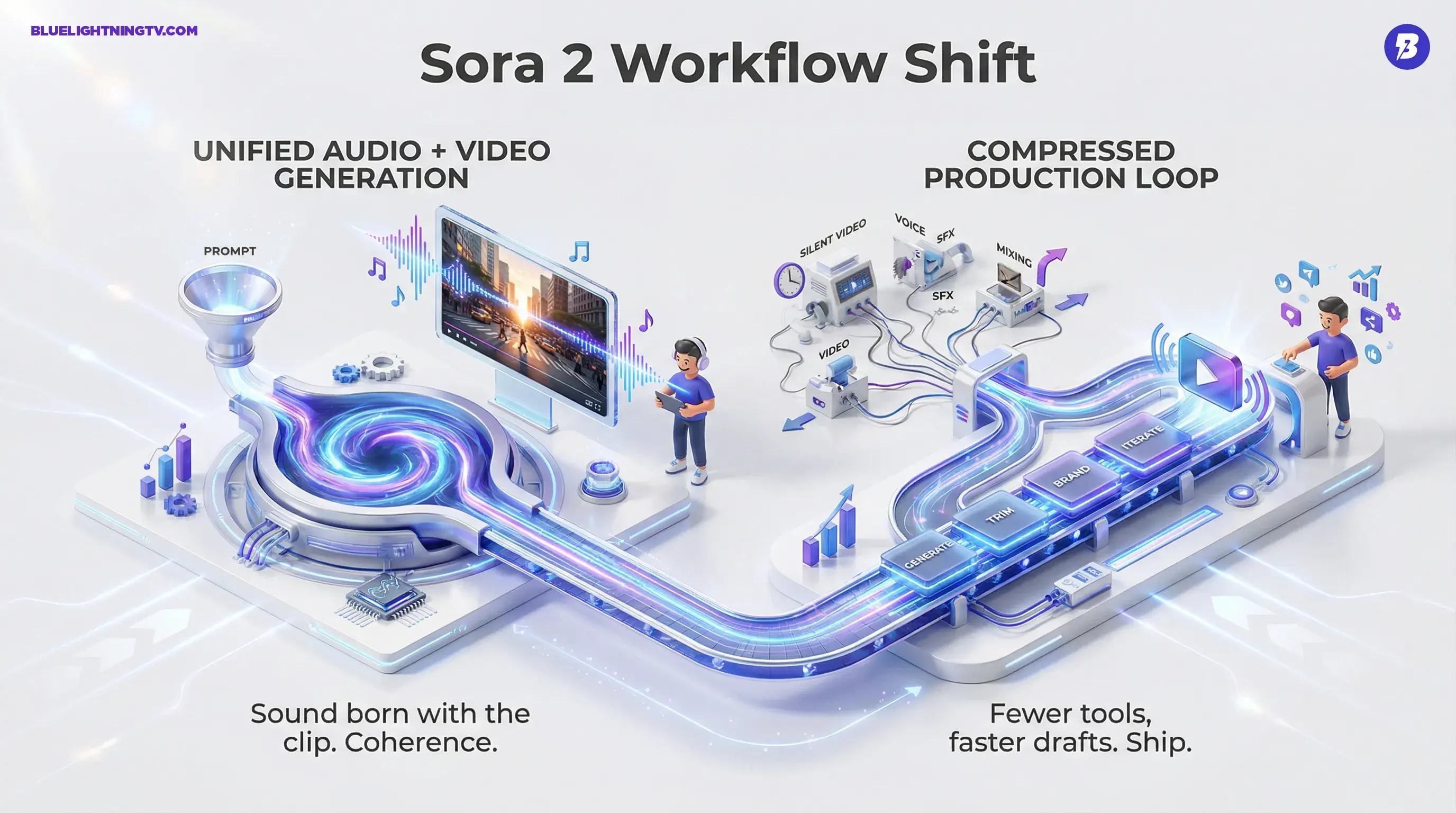
The shift: AI video isn’t just trying to look real anymore. It’s trying to ship.
What OpenAI shipped
Sora 2’s headline feature is simple: native audio generation that matches the video. That means the model is no longer handing you a gorgeous clip that you then have to Frankenstein into something usable with separate voice, music, and SFX tools.
OpenAI also says Sora 2 improves physics, instruction following across shots, and consistency, the stuff that decides whether your character’s hands stay attached to their body and whether your product stays the same shape from frame to frame.
In practical creator terms: Sora 2 is aiming to reduce the two most common AI video pain points:
- Temporal chaos (the “why did the room become a beach?” problem)
- Audio glue work (the “now I need VO + SFX + timing + mix” problem)
The creator-relevant upgrades
OpenAI’s positioning is pretty clear: Sora 2 is meant for short-form production, not just “look what the model can do” demo reels.
Unified audio + video
Sora 2 generates audio as part of the same generation pass as the visuals. That includes:
- Dialogue / speech
- Sound effects
- Ambient soundscapes
- Music-like cues (where allowed and depending on how prompts are interpreted)
The creative win here isn’t just convenience. It’s coherence: when sound is generated with the scene, pacing and tone tend to land better than when you bolt on a random track afterward.
Better motion and physics
OpenAI is emphasizing more believable movement, objects behaving like objects, bodies moving with fewer “rubber limbs,” and scenes that don’t dissolve under mild action.
That matters because most social-first ads, explainers, and brand clips involve motion: hands holding products, walking, turning, interacting. If physics breaks, trust breaks.
Tighter speech-to-mouth alignment
OpenAI is leaning into lip-sync as a key capability. For creators, this is one of those “either it works or it’s unusable” features, especially for direct-to-camera ads, character dialogue, and localized variants.
More controllability
Sora 2 is framed as better at following multi-shot instructions while maintaining consistent elements. That’s the difference between “cool clip” and “sequence you can cut.”
Access and rollout
Sora 2 is rolling out through OpenAI’s Sora experience, with access tied to ChatGPT plans and availability varying by region. OpenAI’s broader Sora access details live here, and usage guidance appears in the OpenAI Help Center here.
Two rollout notes matter if you’re building real workflows:
- Consumer-first access: The early path is UI-first, not pipeline-first.
- API is the unlock: Practical scaling still depends on account access, rate limits, and production readiness.
If you’re a solo creator, UI access is plenty. If you’re a team trying to produce 200 variants of the same concept, scaling becomes the entire story.
What changes in workflows
Sora 2 doesn’t eliminate editing. It changes where editing starts.
Instead of:
- Generate silent clip
- Generate or record voice
- Source music/SFX
- Sync, cut, mix
- Realize the timing is off
- Re-render video
You’re closer to:
- Generate audiovisual draft
- Trim, brand, add overlays
- Iterate prompt for alternates
That shift is especially real for:
- Performance marketers making rapid A/B creative
- Ecommerce teams pumping product hooks
- Agencies pitching concepts before production
- Creators who need volume without turning into a one-person post house
When audio arrives “born with the clip,” the whole production loop compresses.
A quick capability snapshot
Here’s the simplest way to think about Sora 2’s creator impact right now:
| Capability | What Sora 2 changes | Why creators care |
|---|---|---|
| Audio generation | Sound is generated with the video | Fewer tools and faster drafts |
| Dialogue + lip-sync | Speech can align with mouths more reliably | Talking-head and character ads become viable |
| Motion realism | Physics and movement are more believable | Less uncanny footage, fewer unusable renders |
What’s still not solved
Sora 2 is a major step, but it doesn’t magically make production friction disappear.
Brand control is still the tax
Even with better consistency, creators still need to verify:
- Logos don’t mutate
- Product details remain accurate
- Faces and hands don’t drift
- Audio doesn’t introduce weird phrasing or off-tone delivery
The review pass doesn’t go away. It just moves earlier.
Audio can be a blessing and a problem
Native audio is great until it isn’t. If the model generates sound that’s almost right, you can end up spending time removing or replacing it. The win will depend on whether OpenAI gives creators control knobs (audio on/off, stems, dialogue-only, ambience-only, etc.) as the product matures.
Scale hinges on access
UI-first access means most teams can’t always treat Sora 2 like a render engine inside a pipeline. When access expands with workable limits, that’s when Sora 2 becomes less “tool” and more “infrastructure.”
The competitive context
Sora 2 is landing in a market where creator tools are aggressively converging on the same checklist: realism, controllability, vertical formats, and now audio-first generation. Google has been pushing hard in video as well, and if you want a clean comparison point on what the other side is optimizing for, we previously covered Google’s move toward social-native output with Veo 3.1 here.
The bigger takeaway isn’t who’s winning. It’s that AI video is graduating from spectacle to deliverables. Audio is a big part of that graduation, because audiences don’t just watch, they scroll with sound on, or at least they expect it to be there when they tap.
What to watch next
Sora 2’s most important next steps are product decisions, not model flexes:
- Do creators get granular audio controls?
- Does consistency hold across multi-shot sequences?
- How fast does access expand?
- Can teams build repeatable, on-brand outputs without fighting the model?
Sora 2’s core idea, one prompt, one render, picture and sound together, is the right direction for creators who want speed without chaos. The real test is whether it stays impressive after the tenth iteration, when the deadlines are real and the novelty has fully left the building.





