Anthropic has released Claude Sonnet 4.5, positioning the latest Sonnet model as a practical upgrade for creators, developers, and enterprise teams who need reliable AI help across codebases, documents, and multi-app workflows. The announcement details meaningful gains in software engineering benchmarks, computer use, and agent reliability, along with new product features and consistent pricing designed to make adoption straightforward for teams and solo operators. Learn more from Anthropic: Claude Sonnet 4.5.
What’s new at a glance
- Stronger coding performance on real-world issue resolution
- Better hands-on computer use across apps, files, and the web
- New reliability features (checkpoints, rollbacks, memory tooling)
- Expanded agent infrastructure and SDK support
- Flat pricing with broad availability across the Claude ecosystem
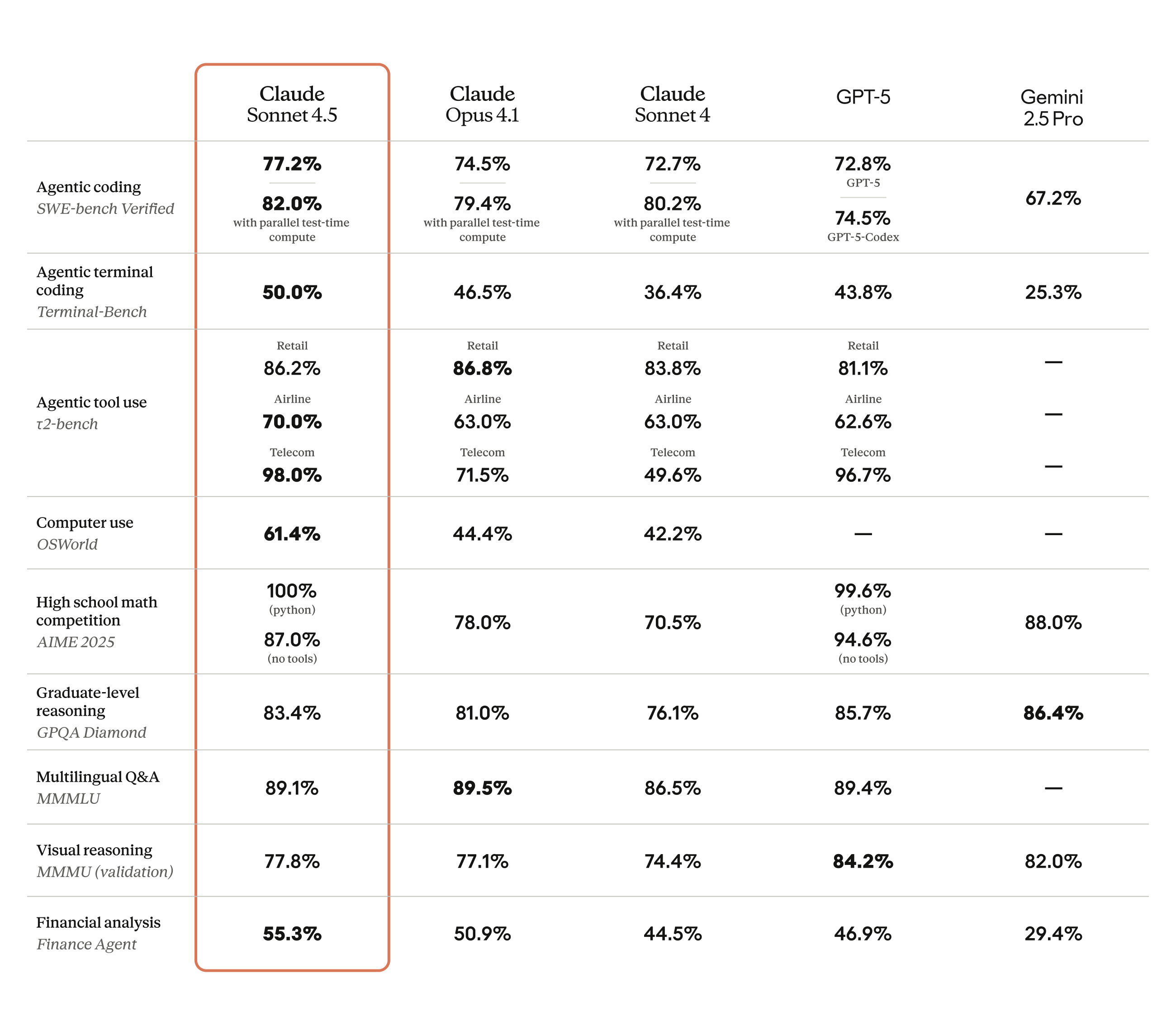
State-of-the-Art Coding Performance
Anthropic frames Sonnet 4.5 as its most capable applied coding model to date. The company cites top performance on SWE-bench Verified – a human-validated benchmark of real software issues – underscoring improvements in not just code generation but also end-to-end bug fixing and maintenance. For context, SWE-bench Verified evaluates models by requiring a working code patch under real test conditions; its design aims to better reflect realistic engineering work than toy problems. More on the benchmark: SWE-bench Verified.
Beyond raw scores, Anthropic emphasizes extended task fidelity. Internal tests point to more coherent, long-horizon reasoning over multi-hour efforts, a capability that matters when a model must carry context across evolving tickets, large repos, and multi-stage tasks. For creative coders and technical content teams, the headline is not just speed – it is the model’s ability to stay on track over time.
Stronger performance on realistic code tasks suggests fewer dead ends and rework for teams shipping features, fixing regressions, or transforming older projects into modern, AI-friendly stacks.
Practical Computer Use and Workflow Automation
Anthropic reports a step-change in real computer interaction, with Sonnet 4.5 leading the OSWorld benchmark – a suite that assesses whether AI agents can reliably use software in authentic desktop and web environments. OSWorld spans hundreds of tasks from file operations to multi-app workflows and browser-based actions. Details on the benchmark are available here: OSWorld.
In practical terms for creators and marketers, this lift translates to smoother handling of spreadsheets, presentations, CMS updates, and cross-tool research. Performance gains in this area are less about novelty and more about day-to-day dependability – the difference between an assistant that can actually do the clicking and one that needs constant hand-holding.
New Tools for Code and Agent Work
Anthropic is pairing the model with product-level features aimed at reducing friction across longer projects and multi-tool pipelines:
- Checkpoints and Instant Rollback in Claude Code to save and revert progress during bigger builds and rewrites.
- Context editing and task memory via the Claude API to maintain continuity across iterative drafts, docs, and multi-stage requests.
- Claude Apps enhancements to run code, generate files, and create structured outputs (like spreadsheets or reports) without leaving the conversation.
- Claude for Chrome extension (for Max users) for on-page assistance – draft, summarize, analyze, or extract without switching contexts.
- Claude Agent SDK to support production-grade, tool-using agents with memory, permissions, and multi-agent coordination.
For teams experimenting with AI assistants that must operate safely and predictably, the SDK’s emphasis on permissioning and state management is an important signal: Anthropic is investing in the infrastructure layer creators and startups need to build dependable agent flows, not just chat.
Reasoning, Safety, and Reliability
Anthropic highlights a broader quality uptick in specialized domains (finance, law, medicine, STEM) and notes further tuning for long-running sessions where traditional models can drift or fail. The company’s focus on alignment and failure-mode reduction is noteworthy for creators who must trust AI with sensitive files, brand voice, and regulated material.
For teams working across large assets – brand guidelines, campaign calendars, pitch decks, or serialized narratives – the push to preserve intent and reduce hallucinations should be felt as fewer course corrections and more usable first drafts.
Pricing and Availability
Anthropic states that Sonnet 4.5 is available now across the Claude API and apps, and that pricing remains consistent with the Sonnet line, lowering friction for teams to adopt the upgrade without budget or procurement changes. For organizations tracking usage and cost controls, Anthropic provides guidance on monitoring and budgeting within Claude Code and API workflows.
Where you can use it today
- Claude API for automation, integrations, and back-end workflows
- Claude desktop and web apps for creative and content workflows
- VS Code and Claude Code experiences for code-centric teams
- Chrome extension (Max users) for web-native productivity
- Agent SDK for building tool-using assistants inside your product
Key Facts Creators Should Know
| Area | What’s New in Sonnet 4.5 | Why It Matters for Creators & Brands |
|---|---|---|
| Coding & Engineering | Top results on SWE-bench Verified; better end-to-end bug fixing and refactoring performance | Faster iteration on websites, plugins, creative tools, and data workflows with fewer regressions |
| Computer Use (OS + Web) | Leads OSWorld benchmark; stronger multi-app tasking and file operations | More dependable spreadsheet, CMS, and presentation work – less micromanagement |
| Reliability Features | Checkpoints, rollbacks, and sustained context via task memory | Lower risk during long edits and campaigns; easier to recover if a direction misfires |
| Agent Infrastructure | Agent SDK with memory, permissions, and multi-agent coordination | Build branded assistants that follow rules, protect data, and scale across teams |
| Access & Pricing | Available across API and apps; pricing consistent with Sonnet line | Upgrade without reworking budgets; predictable cost for scaling usage |
Industry Context
Benchmarks are imperfect proxies for lived workflows, but the combination here – SWE-bench Verified for real code, OSWorld for real computer use – is directionally meaningful. SWE-bench Verified, for example, requires models to propose patches that pass tests in containerized environments, mirroring the realities of fixing production issues. OSWorld, meanwhile, measures whether agents can execute tasks in authentic OS contexts across apps and the web, not just within synthetic sandboxes.
For creators, marketers, and founders, these are not abstract wins. Better agent grounding on the desktop and browser means marketing calendars get assembled faster, client decks finish with fewer format fails, and production checklists can be delegated with higher trust.
If the trend holds, AI that can actually use a computer moves from demo to daily tool, unlocking reliable automation for content ops, campaign reporting, and brand asset management.
Why This Matters for Creators and Brands
- Brand builders: Sonnet 4.5’s improved context retention helps keep tone and messaging consistent across long campaigns and multi-stakeholder edits.
- Content teams: Stronger file handling and multi-app workflows reduce manual formatting, copy and paste, and rework when moving between docs, slides, and web tools.
- Creative technologists: Higher-fidelity coding support shortens time-to-concept for interactive experiences, prototypes, and media tools that blend design with code.
- Solo founders: More dependable desktop and web automation can absorb admin and reporting, freeing time for audience development and product polish.
Video Overview
Bottom Line
Claude Sonnet 4.5 is framed as a practical upgrade for real work: stronger on realistic coding tasks, more capable at everyday computer use, and paired with reliability features and agent infrastructure that matter as teams scale their AI footprint. The headline for creators is not a single flashy feature – it is the cumulative effect of tools that hold context, follow instructions across apps, and recover gracefully when plans change. If adoption matches the benchmarks Anthropic is reporting, Sonnet 4.5 will be a welcome step toward AI that supports the full arc of creative production, from first draft to delivery.





